PdfPig 0.1.9-alpha-20240208-19734
See the version list below for details.
dotnet add package PdfPig --version 0.1.9-alpha-20240208-19734
NuGet\Install-Package PdfPig -Version 0.1.9-alpha-20240208-19734
<PackageReference Include="PdfPig" Version="0.1.9-alpha-20240208-19734" />
<PackageVersion Include="PdfPig" Version="0.1.9-alpha-20240208-19734" />
<PackageReference Include="PdfPig" />
paket add PdfPig --version 0.1.9-alpha-20240208-19734
#r "nuget: PdfPig, 0.1.9-alpha-20240208-19734"
#addin nuget:?package=PdfPig&version=0.1.9-alpha-20240208-19734&prerelease
#tool nuget:?package=PdfPig&version=0.1.9-alpha-20240208-19734&prerelease
<image src="https://raw.githubusercontent.com/UglyToad/Pdf/master/documentation/pdfpig.png" width="128px" height="128px"/>
PdfPig


This project allows users to read and extract text and other content from PDF files. In addition the library can be used to create simple PDF documents containing text and geometrical shapes.
This project aims to port PDFBox to C#.
Migrating to 0.1.6 from 0.1.x? Use this guide: migration to 0.1.6.
Installation
The package is available via the releases tab or from Nuget:
https://www.nuget.org/packages/PdfPig/
Or from the package manager console:
> Install-Package PdfPig
While the version is below 1.0.0 minor versions will change the public API without warning (SemVer will not be followed until 1.0.0 is reached).
Get Started
The simplest usage at this stage is to open a document, reading the words from every page:
using (PdfDocument document = PdfDocument.Open(@"C:\Documents\document.pdf"))
{
foreach (Page page in document.GetPages())
{
string pageText = page.Text;
foreach (Word word in page.GetWords())
{
Console.WriteLine(word.Text);
}
}
}
An example of the output of this is shown below:

Where for the PDF text ("Write something in") shown at the top the 3 words (in pink) are detected and each word contains the individual letters with glyph bounding boxes.
To create documents use the class PdfDocumentBuilder. The Standard 14 fonts provide a quick way to get started:
PdfDocumentBuilder builder = new PdfDocumentBuilder();
PdfPageBuilder page = builder.AddPage(PageSize.A4);
// Fonts must be registered with the document builder prior to use to prevent duplication.
PdfDocumentBuilder.AddedFont font = builder.AddStandard14Font(Standard14Font.Helvetica);
page.AddText("Hello World!", 12, new PdfPoint(25, 700), font);
byte[] documentBytes = builder.Build();
File.WriteAllBytes(@"C:\git\newPdf.pdf", documentBytes);
The output is a 1 page PDF document with the text "Hello World!" in Helvetica near the top of the page:
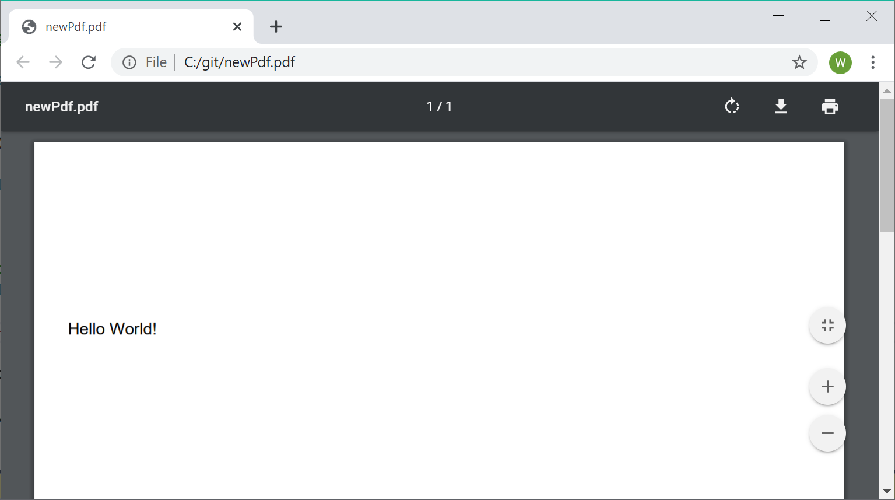
Each font must be registered with the PdfDocumentBuilder prior to use enable pages to share the font resources. Only Standard 14 fonts and TrueType fonts (.ttf) are supported.
Usage
The PdfDocument class provides access to the contents of a document loaded either from file or passed in as bytes. To open from a file use the PdfDocument.Open static method:
using UglyToad.PdfPig;
using UglyToad.PdfPig.Content;
using (PdfDocument document = PdfDocument.Open(@"C:\my-file.pdf"))
{
int pageCount = document.NumberOfPages;
// Page number starts from 1, not 0.
Page page = document.GetPage(1);
decimal widthInPoints = page.Width;
decimal heightInPoints = page.Height;
string text = page.Text;
}
PdfDocument should only be used in a using statement since it implements IDisposable (unless the consumer disposes of it elsewhere).
Encrypted documents can be opened by PdfPig. To provide an owner or user password provide the optional ParsingOptions when calling Open with the Password property defined. For example:
using (PdfDocument document = PdfDocument.Open(@"C:\my-file.pdf", new ParsingOptions { Password = "password here" }))
You can also provide a list of passwords to try:
using (PdfDocument document = PdfDocument.Open(@"C:\file.pdf", new ParsingOptions
{
Passwords = new List<string> { "One", "Two" }
}))
The document contains the version of the PDF specification it complies with, accessed by document.Version:
decimal version = document.Version;
Document Creation (0.0.5)
The PdfDocumentBuilder creates a new document with no pages or content.
For text content, a font must be registered with the builder. This library supports Standard 14 fonts provided by Adobe by default and TrueType format fonts.
To add a Standard 14 font use:
public AddedFont AddStandard14Font(Standard14Font type)
Or for a TrueType font use:
AddedFont AddTrueTypeFont(IReadOnlyList<byte> fontFileBytes)
Passing in the bytes of a TrueType file (.ttf). You can check the suitability of a TrueType file for embedding in a PDF document using:
bool CanUseTrueTypeFont(IReadOnlyList<byte> fontFileBytes, out IReadOnlyList<string> reasons)
Which provides a list of reasons why the font cannot be used if the check fails. You should check the license for a TrueType font prior to use, since the compressed font file is embedded in, and distributed with, the resultant document.
The AddedFont class represents a key to the font stored on the document builder. This must be provided when adding text content to pages. To add a page to a document use:
PdfPageBuilder AddPage(PageSize size, bool isPortrait = true)
This creates a new PdfPageBuilder with the specified size. The first added page is page number 1, then 2, then 3, etc. The page builder supports adding text, drawing lines and rectangles and measuring the size of text prior to drawing.
To draw lines and rectangles use the methods:
void DrawLine(PdfPoint from, PdfPoint to, decimal lineWidth = 1)
void DrawRectangle(PdfPoint position, decimal width, decimal height, decimal lineWidth = 1)
The line width can be varied and defaults to 1. Rectangles are unfilled and the fill color cannot be changed at present.
To write text to the page you must have a reference to an AddedFont from the methods on PdfDocumentBuilder as described above. You can then draw the text to the page using:
IReadOnlyList<Letter> AddText(string text, decimal fontSize, PdfPoint position, PdfDocumentBuilder.AddedFont font)
Where position is the baseline of the text to draw. Currently only ASCII text is supported. You can also measure the resulting size of text prior to drawing using the method:
IReadOnlyList<Letter> MeasureText(string text, decimal fontSize, PdfPoint position, PdfDocumentBuilder.AddedFont font)
Which does not change the state of the page, unlike AddText.
Changing the RGB color of text, lines and rectangles is supported using:
void SetStrokeColor(byte r, byte g, byte b)
void SetTextAndFillColor(byte r, byte g, byte b)
Which take RGB values between 0 and 255. The color will remain active for all operations called after these methods until reset is called using:
void ResetColor()
Which resets the color for stroke, fill and text drawing to black.
Document Information
The PdfDocument provides access to the document metadata as DocumentInformation defined in the PDF file. These tend not to be provided therefore most of these entries will be null:
PdfDocument document = PdfDocument.Open(fileName);
// The name of the program used to convert this document to PDF.
string producer = document.Information.Producer;
// The title given to the document
string title = document.Information.Title;
// etc...
Document Structure (0.0.3)
The document now has a Structure member:
UglyToad.PdfPig.Structure structure = document.Structure;
This provides access to tokenized PDF document content:
Catalog catalog = structure.Catalog;
DictionaryToken pagesDictionary = catalog.PagesDictionary;
The pages dictionary is the root of the pages tree within a PDF document. The structure also exposes a GetObject(IndirectReference reference) method which allows random access to any object in the PDF as long as its identifier number is known. This is an identifier of the form 69 0 R where 69 is the object number and 0 is the generation.
Page
The Page contains the page width and height in points as well as mapping to the PageSize enum:
PageSize size = Page.Size;
bool isA4 = size == PageSize.A4;
Page provides access to the text of the page:
string text = page.Text;
There is a new (0.0.3) method which provides access to the words. This uses basic heuristics and is not reliable or well-tested:
IEnumerable<Word> words = page.GetWords();
You can also (0.0.6) access the raw operations used in the page's content stream for drawing graphics and content on the page:
IReadOnlyList<IGraphicsStateOperation> operations = page.Operations;
Consult the PDF specification for the meaning of individual operators.
There is also an early access (0.0.3) API for retrieving the raw bytes of PDF image objects per page:
IEnumerable<XObjectImage> images = page.ExperimentalAccess.GetRawImages();
This API will be changed in future releases.
Letter
Due to the way a PDF is structured internally the page text may not be a readable representation of the text as it appears in the document. Since PDF is a presentation format, text can be drawn in any order, not necessarily reading order. This means spaces may be missing or words may be in unexpected positions in the text.
To help users resolve actual text order on the page, the Page file provides access to a list of the letters:
IReadOnlyList<Letter> letters = page.Letters;
These letters contain:
- The text of the letter:
letter.Value. - The location of the lower left of the letter:
letter.Location. - The width of the letter:
letter.Width. - The font size in unscaled relative text units (these sizes are internal to the PDF and do not correspond to sizes in pixels, points or other units):
letter.FontSize. - The name of the font used to render the letter if available:
letter.FontName. - A rectangle which is the smallest rectangle that completely contains the visible region of the letter/glyph:
letter.GlyphRectangle. - The points at the start and end of the baseline
StartBaseLineandEndBaseLinewhich indicate if the letter is rotated. TheTextDirectionindicates if this is a commonly used rotation or a custom rotation.
Letter position is measured in PDF coordinates where the origin is the lower left corner of the page. Therefore a higher Y value means closer to the top of the page.
Annotations (0.0.5)
Early support for retrieving annotations on each page is provided using the method:
page.ExperimentalAccess.GetAnnotations()
This call is not cached and the document must not have been disposed prior to use. The annotations API may change in future.
Bookmarks (0.0.10)
The bookmarks (outlines) of a document may be retrieved at the document level:
bool hasBookmarks = document.TryGetBookmarks(out Bookmarks bookmarks);
This will return false if the document does not define any bookmarks.
Forms (0.0.10)
Form fields for interactive forms (AcroForms) can be retrieved using:
bool hasForm = document.TryGetForm(out AcroForm form);
This will return false if the document does not contain a form.
The fields can be accessed using the AcroForm's Fields property. Since the form is defined at the document level this will return fields from all pages in the document. Fields are of the types defined by the enum AcroFieldType, for example PushButton, Checkbox, Text, etc.
Hyperlinks (0.1.0)
A page has a method to extract hyperlinks (annotations of link type):
IReadOnlyList<UglyToad.PdfPig.Content.Hyperlink> hyperlinks = page.GetHyperlinks();
TrueType (0.1.0)
The classes used to work with TrueType fonts in the PDF file are now available for public consumption. Given an input file:
using UglyToad.PdfPig.Fonts.TrueType;
using UglyToad.PdfPig.Fonts.TrueType.Parser;
byte[] fontBytes = System.IO.File.ReadAllBytes(@"C:\font.ttf");
TrueTypeDataBytes input = new TrueTypeDataBytes(fontBytes);
TrueTypeFont font = TrueTypeFontParser.Parse(input);
The parsed font can then be inspected.
Embedded Files (0.1.0)
PDF files may contain other files entirely embedded inside them for document annotations. The list of embedded files and their byte content may be accessed:
if (document.Advanced.TryGetEmbeddedFiles(out IReadOnlyList<EmbeddedFile> files)
&& files.Count > 0)
{
var firstFile = files[0];
string name = firstFile.Name;
IReadOnlyList<byte> bytes = firstFile.Bytes;
}
Merging (0.1.2)
You can merge 2 or more existing PDF files using the PdfMerger class:
var resultFileBytes = PdfMerger.Merge(filePath1, filePath2);
File.WriteAllBytes(@"C:\pdfs\outputfilename.pdf", resultFileBytes);
API Reference
If you wish to generate doxygen documentation, run doxygen doxygen-docs and open docs/doxygen/html/index.html.
Issues
Please do file an issue if you encounter a bug.
However in order for us to assist you, you must provide the file which causes your issue. Please host this in a publically available place.
Credit
This project wouldn't be possible without the work done by the PDFBox team and the Apache Foundation.
| Product | Versions Compatible and additional computed target framework versions. |
|---|---|
| .NET | net5.0 was computed. net5.0-windows was computed. net6.0 is compatible. net6.0-android was computed. net6.0-ios was computed. net6.0-maccatalyst was computed. net6.0-macos was computed. net6.0-tvos was computed. net6.0-windows was computed. net7.0 was computed. net7.0-android was computed. net7.0-ios was computed. net7.0-maccatalyst was computed. net7.0-macos was computed. net7.0-tvos was computed. net7.0-windows was computed. net8.0 was computed. net8.0-android was computed. net8.0-browser was computed. net8.0-ios was computed. net8.0-maccatalyst was computed. net8.0-macos was computed. net8.0-tvos was computed. net8.0-windows was computed. net9.0 was computed. net9.0-android was computed. net9.0-browser was computed. net9.0-ios was computed. net9.0-maccatalyst was computed. net9.0-macos was computed. net9.0-tvos was computed. net9.0-windows was computed. net10.0 was computed. net10.0-android was computed. net10.0-browser was computed. net10.0-ios was computed. net10.0-maccatalyst was computed. net10.0-macos was computed. net10.0-tvos was computed. net10.0-windows was computed. |
| .NET Core | netcoreapp2.0 was computed. netcoreapp2.1 was computed. netcoreapp2.2 was computed. netcoreapp3.0 was computed. netcoreapp3.1 was computed. |
| .NET Standard | netstandard2.0 is compatible. netstandard2.1 was computed. |
| .NET Framework | net451 is compatible. net452 is compatible. net46 is compatible. net461 is compatible. net462 is compatible. net463 was computed. net47 is compatible. net471 was computed. net472 was computed. net48 was computed. net481 was computed. |
| MonoAndroid | monoandroid was computed. |
| MonoMac | monomac was computed. |
| MonoTouch | monotouch was computed. |
| Tizen | tizen40 was computed. tizen60 was computed. |
| Xamarin.iOS | xamarinios was computed. |
| Xamarin.Mac | xamarinmac was computed. |
| Xamarin.TVOS | xamarintvos was computed. |
| Xamarin.WatchOS | xamarinwatchos was computed. |
-
.NETFramework 4.5.1
- System.ValueTuple (>= 4.5.0)
-
.NETFramework 4.5.2
- System.ValueTuple (>= 4.5.0)
-
.NETFramework 4.6
- System.ValueTuple (>= 4.5.0)
-
.NETFramework 4.6.1
- System.ValueTuple (>= 4.5.0)
-
.NETFramework 4.6.2
- System.ValueTuple (>= 4.5.0)
-
.NETFramework 4.7
- System.ValueTuple (>= 4.5.0)
-
.NETStandard 2.0
- No dependencies.
-
net6.0
- No dependencies.
NuGet packages (65)
Showing the top 5 NuGet packages that depend on PdfPig:
| Package | Downloads |
|---|---|
|
Microsoft.KernelMemory.Core
The package contains the core logic and abstractions of Kernel Memory, not including extensions. |
|
|
OrchardCore.Application.Cms.Core.Targets
Orchard Core CMS is a Web Content Management System (CMS) built on top of the Orchard Core Framework. Converts the application into a modular OrchardCore CMS application with TheAdmin theme but without any front-end Themes. |
|
|
Tabula
Extract tables from PDF files (port of tabula-java using PdfPig). |
|
|
OrchardCore.Application.Cms.Targets
Orchard Core CMS is a Web Content Management System (CMS) built on top of the Orchard Core Framework. Converts the application into a modular OrchardCore CMS application with following themes. - TheAdmin Theme - SafeMode Theme - TheAgency Theme - TheBlog Theme - TheComingSoon Theme - TheTheme theme |
|
|
FileCurator
FileCurator is a simple manager for your files. It tries to give them a common interface to deal with files whether on your system or other locations. |
GitHub repositories (23)
Showing the top 20 popular GitHub repositories that depend on PdfPig:
| Repository | Stars |
|---|---|
|
microsoft/semantic-kernel
Integrate cutting-edge LLM technology quickly and easily into your apps
|
|
|
OrchardCMS/OrchardCore
Orchard Core is an open-source modular and multi-tenant application framework built with ASP.NET Core, and a content management system (CMS) built on top of that framework.
|
|
|
dotnet/docfx
Static site generator for .NET API documentation.
|
|
|
SciSharp/BotSharp
AI Multi-Agent Framework in .NET
|
|
|
microsoft/kernel-memory
RAG architecture: index and query any data using LLM and natural language, track sources, show citations, asynchronous memory patterns.
|
|
|
microsoft/ai-dev-gallery
An open-source project for Windows developers to learn how to add AI with local models and APIs to Windows apps.
|
|
|
tryAGI/LangChain
C# implementation of LangChain. We try to be as close to the original as possible in terms of abstractions, but are open to new entities.
|
|
|
getcellm/cellm
Use LLMs in Excel formulas
|
|
|
dotnet/ai-samples
|
|
|
revenz/FileFlows
FileFlows is a file processing application that can execute actions against a file in a tree flow structure.
|
|
|
paillave/Etl.Net
Mass processing data with a complete ETL for .net developers
|
|
|
BobLd/DocumentLayoutAnalysis
Document Layout Analysis resources repos for development with PdfPig.
|
|
|
majorsilence/My-FyiReporting
Majorsilence Reporting, .NET report designer, viewer, and pdf creation. Fork of fyireporting,
|
|
|
KrystynaSlusarczykLearning/UltimateCSharpMasterclass
|
|
|
axzxs2001/Asp.NetCoreExperiment
原来所有项目都移动到**OleVersion**目录下进行保留。新的案例装以.net 5.0为主,一部分对以前案例进行升级,一部分将以前的工作经验总结出来,以供大家参考!
|
|
|
microsoft/project-oagents
Experimental AI Agents Framework
|
|
|
SaboZhang/EasyTidy
EasyTidy A simple file auto-classification tool makes it easy to create automatic workflows with files. / EasyTidy 一个简单的文件自动分类整理工具 轻松创建文件的自动工作流程
|
|
|
microsoft/hidtools
Human Interface Device (HID) Tools for Windows and Devices
|
|
|
SteveSandersonMS/dotnet-ai-workshop
|
|
|
BobLd/tabula-sharp
Extract tables from PDF files (port of tabula-java)
|