ManySpeech.AliParaformerAsr
1.1.9
dotnet add package ManySpeech.AliParaformerAsr --version 1.1.9
NuGet\Install-Package ManySpeech.AliParaformerAsr -Version 1.1.9
<PackageReference Include="ManySpeech.AliParaformerAsr" Version="1.1.9" />
<PackageVersion Include="ManySpeech.AliParaformerAsr" Version="1.1.9" />
<PackageReference Include="ManySpeech.AliParaformerAsr" />
paket add ManySpeech.AliParaformerAsr --version 1.1.9
#r "nuget: ManySpeech.AliParaformerAsr, 1.1.9"
#:package ManySpeech.AliParaformerAsr@1.1.9
#addin nuget:?package=ManySpeech.AliParaformerAsr&version=1.1.9
#tool nuget:?package=ManySpeech.AliParaformerAsr&version=1.1.9
ManySpeech.AliParaformerAsr User Guide
I. Introduction
ManySpeech.AliParaformerAsr is a "speech recognition" library written in C#. It decodes ONNX models by calling Microsoft.ML.OnnxRuntime at the bottom layer. It has several notable features:
- Multi-environment Support: It is compatible with multiple environments such as net461+, net60+, netcoreapp3.1, and netstandard2.0+, meeting the needs of different development scenarios.
- Cross-platform Compilation: It supports cross-platform compilation, enabling it to be compiled and used on various operating systems like Windows, macOS, Linux, and Android, thus expanding its application range.
- AOT Compilation Support: It is simple and convenient to use, facilitating developers to quickly integrate it into their projects.
II. Installation Methods
It is recommended to install via the NuGet package manager. There are two specific installation approaches as follows:
(A) Using Package Manager Console
Execute the following command in the "Package Manager Console" of Visual Studio:
Install-Package ManySpeech.AliParaformerAsr
(B) Using.NET CLI
Enter the following command in the command line to install:
dotnet add package ManySpeech.AliParaformerAsr
III. Configuration Instructions (Refer to the asr.yaml File)
In the asr.yaml configuration file used for decoding, most parameters do not need to be modified. However, there is a specific modifiable parameter:
use_itn: true: When using the SenseVoiceSmall model configuration, enabling this parameter can achieve inverse text normalization. For example, it can convert text like "123" into "one hundred and twenty-three", making the recognized text more in line with the normal reading habits.
IV. Code Calling Methods
(A) Offline (Non-streaming) Model Calling
- Adding Project References Add the following references in the code:
using ManySpeech.AliParaformerAsr;
using ManySpeech.AliParaformerAsr.Model;
- Model Initialization and Configuration
- Initialization Method for the paraformer Model:
string applicationBase = AppDomain.CurrentDomain.BaseDirectory;
string modelName = "speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx";
string modelFilePath = applicationBase + "./" + modelName + "/model_quant.onnx";
string configFilePath = applicationBase + "./" + modelName + "/asr.yaml";
string mvnFilePath = applicationBase + "./" + modelName + "/am.mvn";
string tokensFilePath = applicationBase + "./" + modelName + "/tokens.txt";
OfflineRecognizer offlineRecognizer = new OfflineRecognizer(modelFilePath, configFilePath, mvnFilePath, tokensFilePath);
- **Initialization Method for the SeACo-paraformer Model**:
- First, find the hotword.txt file in the model directory and add custom hotwords in the format of one Chinese word per line, such as adding industry-specific terms, specific personal names, and other hotword content.
- Then, add relevant parameters in the code. The example is as follows:
string applicationBase = AppDomain.CurrentDomain.BaseDirectory;
string modelName = "paraformer-seaco-large-zh-timestamp-onnx-offline";
string modelFilePath = applicationBase + "./" + modelName + "/model.int8.onnx";
string modelebFilePath = applicationBase + "./" + modelName + "/model_eb.int8.onnx";
string configFilePath = applicationBase + "./" + modelName + "/asr.yaml";
string mvnFilePath = applicationBase + "./" + modelName + "/am.mvn";
string hotwordFilePath = applicationBase + "./" + modelName + "/hotword.txt";
string tokensFilePath = applicationBase + "./" + modelName + "/tokens.txt";
OfflineRecognizer offlineRecognizer = new OfflineRecognizer(modelFilePath: modelFilePath, configFilePath: configFilePath, mvnFilePath, tokensFilePath: tokensFilePath, modelebFilePath: modelebFilePath, hotwordFilePath: hotwordFilePath);
- Calling Process
List<float[]> samples = new List<float[]>();
// The code for converting the wav file into samples is omitted here. For details, refer to the example code in ManySpeech.AliParaformerAsr.Examples.
List<OfflineStream> streams = new List<OfflineStream>();
foreach (var sample in samples)
{
OfflineStream stream = offlineRecognizer.CreateOfflineStream();
stream.AddSamples(sample);
streams.Add(stream);
}
List<OfflineRecognizerResultEntity> results = offlineRecognizer.GetResults(streams);
- Example of Output Results
Welcome everyone to experience the speech recognition model launched by DAMO Academy.
It's very convenient, but now it's different. The UK has left the EU, and the EU has an internal industrial chain with good dividends.
He must be home now for the light is on. (He must be at home because the light is on.) It's like there's a kind of reasoning or explanation for that feeling.
elapsed_milliseconds: 1502.8828125
total_duration: 40525.6875
rtf: 0.037084696280599808
end!
(B) Real-time (Streaming) Model Calling
- Adding Project References Add the following references in the code as well:
using ManySpeech.AliParaformerAsr;
using ManySpeech.AliParaformerAsr.Model;
- Model Initialization and Configuration
string encoderFilePath = applicationBase + "./" + modelName + "/encoder.int8.onnx";
string decoderFilePath = applicationBase + "./" + modelName + "/decoder.int8.onnx";
string configFilePath = applicationBase + "./" + modelName + "/asr.yaml";
string mvnFilePath = applicationBase + "./" + modelName + "/am.mvn";
string tokensFilePath = applicationBase + "./" + modelName + "/tokens.txt";
OnlineRecognizer onlineRecognizer = new OnlineRecognizer(encoderFilePath, decoderFilePath, configFilePath, mvnFilePath, tokensFilePath);
- Calling Process
List<float[]> samples = new List<float[]>();
// The code for converting the wav file into samples is omitted here. The following is the sample code for batch processing:
List<OnlineStream> streams = new List<OnlineStream>();
OnlineStream stream = onlineRecognizer.CreateOnlineStream();
foreach (var sample in samples)
{
OnlineStream stream = onlineRecognizer.CreateOnlineStream();
stream.AddSamples(sample);
streams.Add(stream);
}
List<OnlineRecognizerResultEntity> results = onlineRecognizer.GetResults(streams);
// Example of single processing. Only one stream needs to be constructed.
OnlineStream stream = onlineRecognizer.CreateOnlineStream();
stream.AddSamples(sample);
OnlineRecognizerResultEntity result = onlineRecognizer.GetResult(stream);
// Refer to the example code in ManySpeech.AliParaformerAsr.Examples for details.
- Example of Output Results
It is precisely because of the existence of absolute justice that I accept the relative justice in reality, but don't deny the absolute justice just because of the relative justice in reality.
elapsed_milliseconds: 1389.3125
total_duration: 13052
rtf: 0.10644441464909593
Hello, World!
V. Related Projects
- Voice Activity Detection: To solve the problem of reasonable segmentation of long audio, you can add the ManySpeech.AliFsmnVad library and install it with the following command:
dotnet add package ManySpeech.AliFsmnVad
- Text Punctuation Prediction: To address the lack of punctuation in recognition results, you can add the ManySpeech.AliCTTransformerPunc library. The installation command is as follows:
dotnet add package ManySpeech.AliCTTransformerPunc
Specific calling examples can be referred to in the official documentation of the corresponding libraries or the ManySpeech.AliParaformerAsr.Examples project. This project is a console/desktop example project mainly used to demonstrate the basic functions of speech recognition, such as offline transcription and real-time recognition.
VI. Other Notes
- Test Cases: Use
ManySpeech.AliParaformerAsr.Examplesas the test case. - Test CPU: The test CPU used is Intel(R) Core(TM) i7-10750H CPU @ 2.60GHz (2.59 GHz).
- Supported Platforms:
- Windows: Windows 7 SP1 and higher versions.
- macOS: macOS 10.13 (High Sierra) and higher versions, and also supports iOS, etc.
- Linux: Applicable to Linux distributions, but specific dependencies need to be met (see the list of Linux distributions supported by.NET 6 for details).
- Android: Supports Android 5.0 (API 21) and higher versions.
VII. Model Download (Supported ONNX Models)
The following is the information related to the ONNX models supported by ManySpeech.AliParaformerAsr, including model names, types, supported languages, punctuation status, timestamp status, and download addresses, which facilitates you to choose the appropriate model for download and use according to specific requirements:
| Model Name | Type | Supported Languages | Punctuation | Timestamp | Download Address |
|---|---|---|---|---|---|
| paraformer-large-zh-en-onnx-offline | Non-streaming | Chinese, English | No | No | huggingface, modelscope |
| paraformer-large-zh-en-timestamp-onnx-offline | Non-streaming | Chinese, English | No | Yes | modelscope |
| paraformer-large-en-onnx-offline | Non-streaming | English | No | No | modelscope |
| paraformer-large-zh-en-onnx-online | Streaming | Chinese, English | No | No | modelscope |
| paraformer-large-zh-yue-en-timestamp-onnx-offline-dengcunqin-20240805 | Non-streaming | Chinese, Cantonese, English | No | Yes | modelscope |
| paraformer-large-zh-yue-en-onnx-offline-dengcunqin-20240805 | Non-streaming | Chinese, Cantonese, English | No | No | modelscope |
| paraformer-large-zh-yue-en-onnx-online-dengcunqin-20240208 | Streaming | Chinese, Cantonese, English | No | No | modelscope |
| paraformer-seaco-large-zh-timestamp-onnx-offline | Non-streaming | Chinese, Hotwords | No | Yes | modelscope |
| SenseVoiceSmall | Non-streaming | Chinese, Cantonese, English, Japanese, Korean | Yes | No | modelscope, modelscope-split-embed |
| sensevoice-small-wenetspeech-yue-int8-onnx | Non-streaming | Cantonese, Chinese, English, Japanese, Korean | Yes | No | modelscope |
VIII. Model Introduction
(A) Model Usage
Paraformer is an efficient non-autoregressive end-to-end speech recognition framework proposed by the speech team of DAMO Academy. The Paraformer Chinese general-purpose speech recognition model in this project is trained with tens of thousands of hours of labeled audio in the industrial field, which endows the model with good general recognition performance. It can be widely applied in scenarios such as speech input methods, speech navigation, and intelligent meeting minutes, and has a relatively high recognition accuracy.
(B) Model Structure
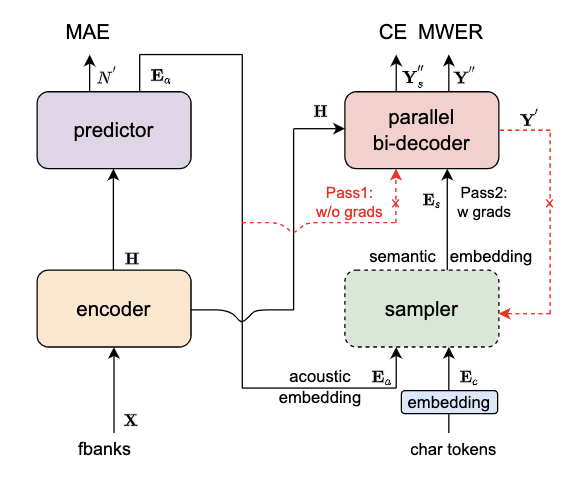
The Paraformer model structure mainly consists of five parts: Encoder, Predictor, Sampler, Decoder, and Loss function. You can view its structural diagram here. The specific functions of each part are as follows:
{kind=link}
- Encoder: It can adopt different network structures, such as self-attention, conformer, SAN-M, etc., and is mainly responsible for extracting acoustic features from audio.
- Predictor: It is a two-layer FFN (Feed Forward Neural Network). Its function is to predict the number of target words and extract the acoustic vectors corresponding to the target words, providing key data for subsequent recognition processing.
- Sampler: It is a module without learnable parameters. It can generate semantic feature vectors based on the input acoustic vectors and target vectors, enriching the semantic information for recognition.
- Decoder: Its structure is similar to that of the autoregressive model, but it is a bidirectional modeling (while the autoregressive model is unidirectional modeling). Through the bidirectional structure, it can better model the context and improve the accuracy of speech recognition.
- Loss function: Besides including the Cross Entropy (CE) and Minimum Word Error Rate (MWER) as discriminative optimization objectives, it also covers the Predictor optimization objective Mean Absolute Error (MAE). These optimization objectives ensure the accuracy of the model.
(C) Main Highlights
- Predictor Module: Based on the Continuous integrate-and-fire (CIF) predictor, it extracts the acoustic feature vectors corresponding to the target words. In this way, it can predict the number of target words in the speech more accurately and improve the accuracy of speech recognition.
- Sampler: Through the sampling operation, it transforms the acoustic feature vectors and target word vectors into semantic feature vectors. Then, in cooperation with the bidirectional Decoder, it can significantly enhance the model's ability to understand and model the context, making the recognition results more in line with semantic logic.
- MWER Training Criterion Based on Negative Sample Sampling: This training criterion helps the model optimize parameters better during the training process, reduces recognition errors, and improves the overall recognition performance.
(D) More Detailed Information
- Model Links:
- Paper: Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition
- Paper Interpretation: Paraformer: High Recognition Rate and High Computational Efficiency Single-round Non-autoregressive End-to-End Speech Recognition Model
Reference [1] https://github.com/alibaba-damo-academy/FunASR
| Product | Versions Compatible and additional computed target framework versions. |
|---|---|
| .NET | net5.0 was computed. net5.0-windows was computed. net6.0 is compatible. net6.0-android was computed. net6.0-ios was computed. net6.0-maccatalyst was computed. net6.0-macos was computed. net6.0-tvos was computed. net6.0-windows was computed. net7.0 was computed. net7.0-android was computed. net7.0-ios was computed. net7.0-maccatalyst was computed. net7.0-macos was computed. net7.0-tvos was computed. net7.0-windows was computed. net8.0 is compatible. net8.0-android was computed. net8.0-android34.0 is compatible. net8.0-browser was computed. net8.0-ios was computed. net8.0-ios18.0 is compatible. net8.0-maccatalyst was computed. net8.0-maccatalyst18.0 is compatible. net8.0-macos was computed. net8.0-tvos was computed. net8.0-windows was computed. net8.0-windows10.0.19041 is compatible. net9.0 was computed. net9.0-android was computed. net9.0-browser was computed. net9.0-ios was computed. net9.0-maccatalyst was computed. net9.0-macos was computed. net9.0-tvos was computed. net9.0-windows was computed. net10.0 was computed. net10.0-android was computed. net10.0-browser was computed. net10.0-ios was computed. net10.0-maccatalyst was computed. net10.0-macos was computed. net10.0-tvos was computed. net10.0-windows was computed. |
| .NET Core | netcoreapp2.0 was computed. netcoreapp2.1 was computed. netcoreapp2.2 was computed. netcoreapp3.0 was computed. netcoreapp3.1 is compatible. |
| .NET Standard | netstandard2.0 is compatible. netstandard2.1 is compatible. |
| .NET Framework | net461 is compatible. net462 was computed. net463 was computed. net47 was computed. net471 was computed. net472 is compatible. net48 is compatible. net481 was computed. |
| MonoAndroid | monoandroid was computed. |
| MonoMac | monomac was computed. |
| MonoTouch | monotouch was computed. |
| Tizen | tizen40 was computed. tizen60 was computed. |
| Xamarin.iOS | xamarinios was computed. |
| Xamarin.Mac | xamarinmac was computed. |
| Xamarin.TVOS | xamarintvos was computed. |
| Xamarin.WatchOS | xamarinwatchos was computed. |
-
.NETCoreApp 3.1
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- System.Text.Json (>= 9.0.8)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
.NETFramework 4.6.1
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- System.Text.Json (>= 9.0.8)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
.NETFramework 4.7.2
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- System.Text.Json (>= 9.0.8)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
.NETFramework 4.8
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- System.Text.Json (>= 9.0.8)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
.NETStandard 2.0
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- System.Text.Json (>= 9.0.8)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
.NETStandard 2.1
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- System.Text.Json (>= 9.0.8)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
net6.0
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
net8.0
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
net8.0-android34.0
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
net8.0-ios18.0
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
net8.0-maccatalyst18.0
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
-
net8.0-windows10.0.19041
- ManySpeech.SpeechFeatures (>= 1.1.7)
- Microsoft.ML.OnnxRuntime (>= 1.22.1)
- Vecc.YamlDotNet.Analyzers.StaticGenerator (>= 16.3.0)
- YamlDotNet (>= 16.3.0)
NuGet packages
This package is not used by any NuGet packages.
GitHub repositories
This package is not used by any popular GitHub repositories.
| Version | Downloads | Last Updated |
|---|---|---|
| 1.1.9 | 77 | 10/13/2025 |
| 1.1.8 | 187 | 9/23/2025 |
| 1.1.7 | 226 | 8/26/2025 |
| 1.1.6 | 94 | 8/23/2025 |
| 1.1.5 | 94 | 8/23/2025 |
| 1.1.4 | 162 | 8/19/2025 |
| 1.1.3 | 161 | 8/19/2025 |
| 1.1.2 | 175 | 8/18/2025 |
| 1.1.1 | 116 | 8/15/2025 |
| 1.1.0 | 118 | 8/15/2025 |
| 1.0.9 | 151 | 8/15/2025 |
| 1.0.8 | 162 | 8/11/2025 |
| 1.0.7 | 163 | 8/11/2025 |
| 1.0.6 | 239 | 8/6/2025 |
| 1.0.5 | 240 | 8/6/2025 |
| 1.0.4 | 326 | 6/10/2025 |